Object storage (also referred to as object-based storage) is a general term that refers to the way in which we organize and work with units of storage, called objects. Every object contains three things:
The data itself. The data can be anything you want to store, from a family photo to a 400,000-page manual for assembling an aircraft.
An expandable amount of metadata. The metadata is defined by whoever creates the object storage; it contains contextual information about what the data is, what it should be used for, its confidentiality, or anything else that is relevant to the way in which the data is used.
A globally unique identifier. The identifier is an address given to the object in order for the object to be found over a distributed system. This way, it’s possible to find the data without having to know the physical location of the data (which could exist within different parts of a data center or different parts of the world).
How block storage and object storage differ
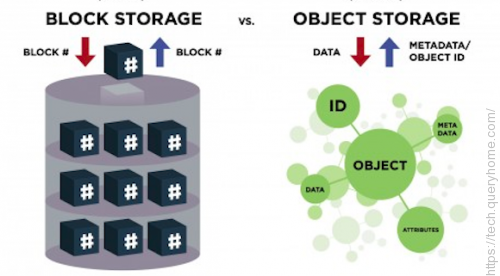
block storage and object storage, block storage vs object storage, block storage vs. object storage, object storage vs block storage, object vs block storage
With block storage, files are split into evenly sized blocks of data, each with its own address but with no additional information (metadata) to provide more context for what that block of data is. You’re likely to encounter block storage in the majority of enterprise workloads; it has a wide variety of uses (as seen by the rise in popularity of SAN arrays).
Object storage, by contrast, doesn’t split files up into raw blocks of data. Instead, entire clumps of data are stored in, yes, an object that contains the data, metadata, and the unique identifier. There is no limit on the type or amount of metadata, which makes object storage powerful and customizable. Metadata can include anything from the security classification of the file within the object to the importance of the application associated with the information. Anyone who’s stored a picture on Facebook or a song on Spotify has used object storage even if they don’t know it. In the enterprise data center, object storage is used for these same types of storage needs, where the data needs to be highly available and highly durable.
However, object storage generally doesn’t provide you with the ability to incrementally edit one part of a file (as block storage does). Objects have to be manipulated as a whole unit, requiring the entire object to be accessed, updated, then re-written in their entirety. That can have performance implications.
Another key difference is that block storage can be directly accessed by the operating system as a mounted drive volume, while object storage cannot do so without significant degradation to performance. The trade off here is that, with object storage, the storage management overhead of block storage (such as remapping volumes) is relatively nonexistent.

