With a steep rise in NoSQL databases, several organizations are making a transition from traditional databases to open-source, distributed and high performance ones like ‘Cassandra’. Since its origin at Facebook in 2008 by Prashant Malik and Avinash Lakshman, Cassandra has become Apache’s one of the most popular projects. And why not? With the unique capacity to deliver near real-time performance, Cassandra makes lives of Web Developers, Software Engineers and Data Analysts far easier than it was in the company of traditional RDBMS. The wonders Cassandra is creating in the Big Data industry is phenomenal!
Let’s look at some of the Cassandra advantages and why companies like Facebook, eBay, Reddit, Twitter, NetFlix, IBM and several others are using Cassandra?
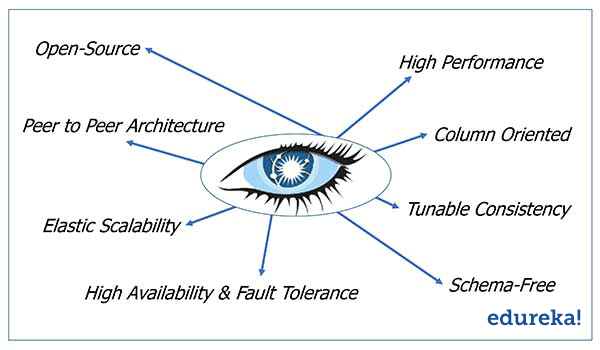
Apache Cassandra Advantages:
1.Open Source

Cassandra is Apache’s open-source project, this means it is available for FREE! Yes, you can download the application and use the way you want. Infact, its open-source nature has given birth to a huge Cassandra community where like-minded people share their views, queries, suggestions related to Big Data. Further, Cassandra can be integrated with other Apache open-source projects like Hadoop (with the help of MapReduce), Apache Pig and Apache Hive.
2. Peer to Peer Architecture:

Cassandra follows a peer-to-peer architecture, instead of master-slave architecture. Hence, there is no single point of failure in Cassandra. Moreover, any number of servers/nodes can be added to any Cassandra cluster in any of the datacenters. As all the machines are at equal level, any server can entertain request from any client. Undoubtedly, with its robust architecture and exceptional characteristics, Cassandra has raised the bar far above than other databases.
3. Elastic Scalability:

One of the biggest advantages of using Cassandra is its elastic scalability. Cassandra cluster can be easily scaled-up or scaled-down. Interestingly, any number of nodes can be added or deleted in Cassandra cluster without much disturbance. You don’t have to restart the cluster or change queries related Cassandra application while scaling up or down. This is why Cassandra is popular of having a very high throughput for the highest number of nodes. As scaling happens, read and write throughput both increase simultaneously with zero downtime or any pause to the applications.
4. High Availability and Fault Tolerance:

Another striking feature of Cassandra is Data replication which makes Cassandra highly available and fault-tolerant. Replication means each data is stored at more than one location. This is because, even if one node fails, the user should be able to retrieve the data with ease from another location. In a Cassandra cluster, each row is replicated based on the row key. You can set the number of replicas you want to create. Just like scaling, data replication can also happen across multiple data centres. This further leads to high level back-up and recovery competencies in Cassandra.
5. High Performance:

The basic idea behind developing Cassandra was to harness the hidden capabilities of several multicore machines. Cassandra has made this dream come true! Cassandra has demonstrated brilliant performance under large sets of data. Thus, Cassandra is loved by those organizations that deal with huge amount of data every day and at the same time cannot afford to lose such data.
6. Column Oriented:
Cassandra has a very high-level data model – this is column-oriented. It means, Cassandra stores columns based on the column names, leading to very quick slicing. Unlike traditional databases, where column names only consist of metadata, in Cassandra column names can also consist of the actual data. Thus, Cassandra rows can consist of masses of columns, in contrast to a relational database that consists of a few number of columns. Cassandra is endowed with a rich data model.
7. Tunable Consistency:

Characteristics like Tunable Consistency, makes Cassandra an incomparable database. In Cassandra, Consistency can be of two types – Eventual consistency and Strong consistency. You can adopt any of these, based on your requirements. Eventual consistency makes sure that the client is approved as soon as the cluster accepts the write. Whereas, Strong consistency means that any update is broadcasted to all machines or all the nodes where the particular data is situated. You also have the freedom to blend both eventual and strong consistency. For instance, you can go for eventual consistency in case of remote data centers where latency is quite high and go for Strong consistency for local data centers where latency is low.
8. Schema-Free:

Since its creation, Cassandra is famous for being a Schema-less/schema-free database in its column family. In Cassandra, columns can be created at your will within the rows. Cassandra data model is also famously known as a schema-optional data model. In contrast to a traditional database, in Cassandra there is no need to show all the columns needed by your application at the surface as each row is not expected to have the same set of columns.
It is because of the above reasons, Cassandra is in great demand among several companies, where MySQL is getting replaced by NoSQL databases. A database that was initially created to solve the inbox search issues at Facebook, has come a long way to solve Big Data problems. Today, Cassandra is used in diverse applications…whether it is streaming videos or supporting various business units or production applications.
Cassandra is Today’s Big Data Solution.....!!!!!

